
Conduit Elector Brings High Availability Sequencers and Zero Downtime Deployments to the Superchain
We’re excited to announce that after months of trialing an in-house implementation, Conduit has developed a new technology called Elector that allows for OP Stack sequencers to run in a high availability configuration with automated failover.


We’re excited to announce that after months of trialing an in-house implementation, Conduit has developed a new technology called Elector that allows for OP Stack sequencers to run in a high availability configuration with automated failover. This allows us to offer 99.95%+ SLAs to every Conduit OP Chain, setting the industry standard.
Running a single node sequencer setup, or even multiple sequencers with manual failover, makes offering best-in-class SLAs impossible, since you’re beholden to the SLA for one node failing which is typically 99.9%.
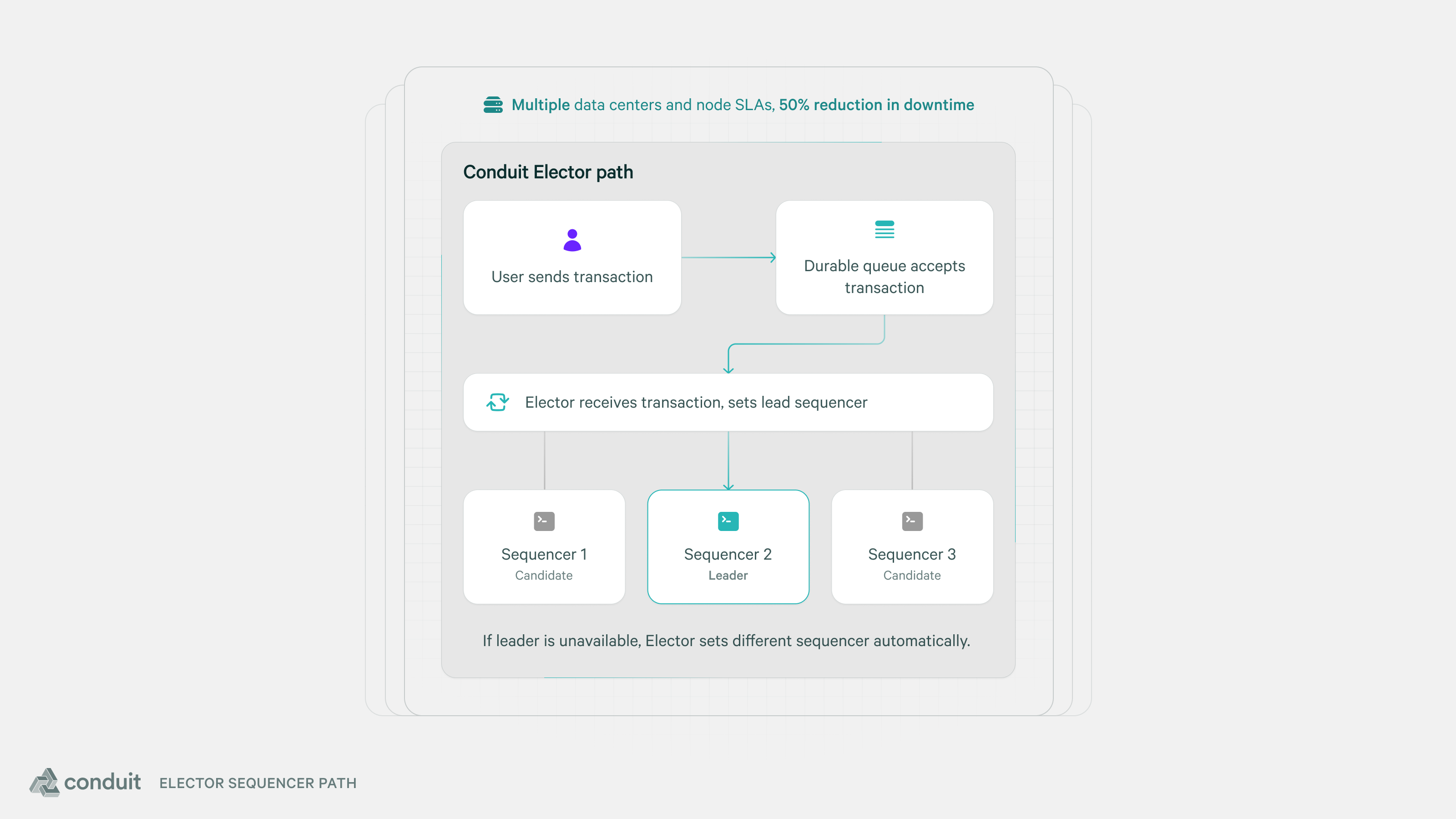
With Elector, Conduit runs three sequencers spread across datacenters that can dynamically decide who is currently producing blocks for the network. This allows us to push beyond a single node SLA to a multiple node SLA to reduce downtime by more than 50%.
Elector also allows Conduit to roll out software and infrastructure upgrades automatically with zero downtime. All Conduit OP Chains have been upgraded to use Elector and all new Conduit OP Chains will enjoy the Elector upgrade from genesis.
Sequencer Downtime Explained
The OP stack standard configuration only comes with one sequencer. This means that if you need to make an update to the software, or if the node hosting your sequencer suffers hardware failure, then you will have sequencer downtime where the network is no longer producing any blocks. This means that transactions get delayed and users can’t interact with the blockchain.
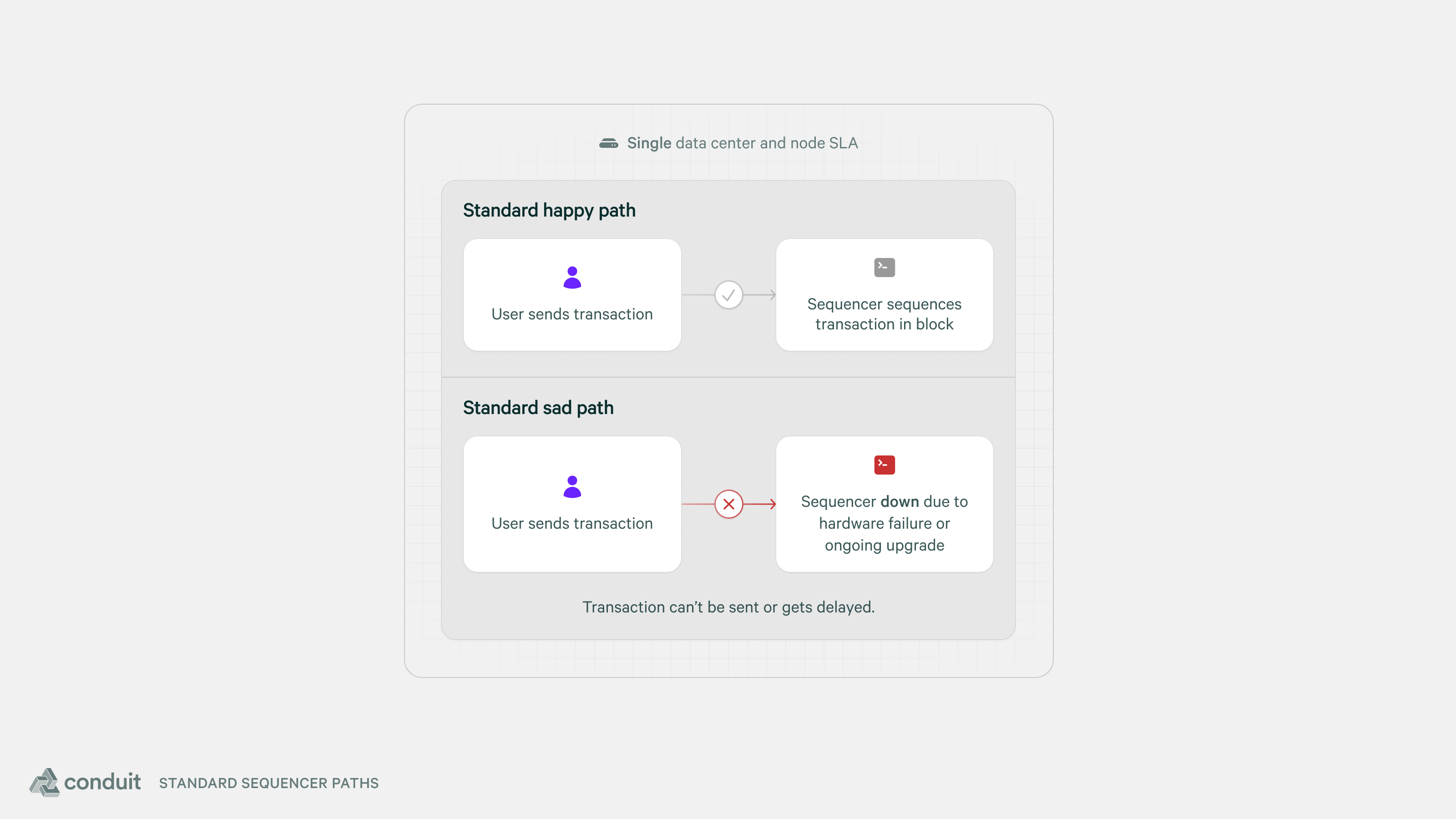
An attempt at adding more reliability might look like adding multiple sequencer candidates as standbys, but failover typically requires additional infrastructure and manual intervention. Manual intervention tends to rely on alerting, which means that recovery times may lag into the tens of minutes, or even longer than an hour.
While manual intervention may be feasible if you’re running a single rollup network, for Conduit, where we run hundreds of chains across testnet and mainnet, we needed to build an automated solution.
Enter Conduit Elector
Conduit Elector is an automated election protocol that runs as a consensus layer on top of the OP Stack that decides which sequencer is currently producing blocks for the network.
Sequencers can give up their leadership preemptively, as they might do when their code is getting upgraded, which will allow a new sequencer to seamlessly step up to become the leader. Or if a hardware failure causes a sequencer to go down, Elector will notice after the leadership timeout and elect a new sequencer to produce blocks.
We’ve deeply integrated Elector with Kubernetes (K8s) to match the lifecycle of deployments, terminations, and other types of cloud-native events in order to maximize the resilience of Conduit OP Chains.
Higher SLAs and Automated Upgrades
With Conduit Elector we offer 99.95%+ SLAs out of the box for every Conduit OP Chain. This means that we can finally offer our best-in-class Enterprise Tier SLAs for every customer.
Elector also allows us to roll out upgrades, configuration changes, or hard forks with zero downtime. No longer are upgrades a scary all-hands-on-deck event, instead they can become business as usual.
With Elector, Conduit continues to push the boundary of what’s possible on the infrastructure front for rollups. If this type of engineering work deep in the stack is interesting to you, please reach out. Or if you’d like to deploy a rollup with Conduit, check out our self-serve Rollups-as-a-Service (RaaS) platform.